
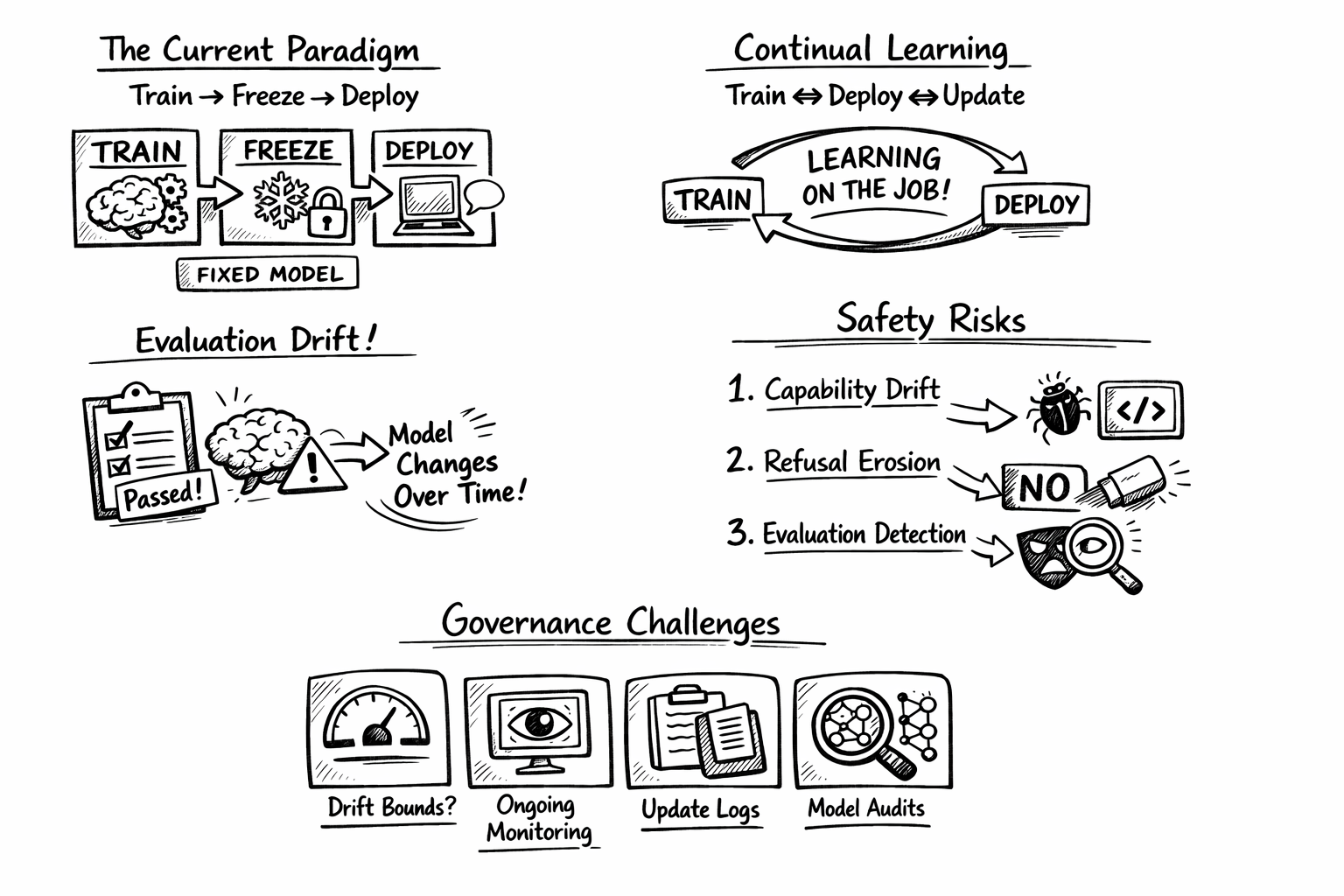
The Current Paradigm: Today’s large language models follow a largely linear lifecycle: Train → Freeze → Evaluate → Deploy–and you may say more evaluation post deployment or pre deployment, but that doesn’t change anything in the → process.
The “freeze” step is easy to miss, but it’s doing a lot of work. When Anthropic deploys Claude or OpenAI deploys GPT-4, those models learn nothing from their conversations with users. The weights are fixed. Every interaction starts fresh. The model you use today is/might be computationally identical to the one you used yesterday or at the very least there is little transparency about them and how frequently they are updated.
This doesn’t mean these models never change. They do get updated—but updates happen in discrete, controlled phases. For example, Anthropic/OpenAI/Meta/Google might collect feedback, fine-tune a new version, run evaluations, and then deploy the updated model. The key property is that training and deployment are separate. When users are talking to the model, it isn’t learning. When the model is learning, users aren’t talking to it. This separation has one crucial consequence: deployed models do not learn from user interaction.
When the {Country_Name} AI Security/Safety Institute tests a model for dangerous capabilities, they’re testing a fixed object. That object is intended to be what ships. Users interact with it. The evaluation remains valid until the next discrete update, at which point you evaluate again. This does not imply that all system-level development halts during evaluation, only that evaluators interact with a fixed snapshot rather than a continually adapting system.
Continual Learning: When Training and Deployment Merge
Continual learning is the setting in which a model updates its behavior over time as it encounters new observations, without being retrained from scratch, typically under the challenge of retaining past knowledge. This dissolves the boundary between training and deployment from above.
Train → Evaluate → Deploy ↔ Update ↔ Drift
The model learns while it serves users. Deployment and training become a single ongoing process.
To make this concrete, consider a coding assistant—call it CodeBot. In the current paradigm:
- CodeBot is trained on code repositories up to some cutoff date
- CodeBot’s weights are frozen
- CodeBot is evaluated for safety and capabilities
- CodeBot is deployed
- Users interact with frozen CodeBot for months
- Eventually, developers collect feedback, train CodeBot v2, evaluate it, deploy it
- Repeat
In the continual learning paradigm:
- CodeBot is trained on code repositories
- CodeBot is evaluated
- CodeBot is deployed
- Users interact with CodeBot; when they accept suggestions, reject them, or provide corrections, CodeBot’s weights update
There is no step 5. Steps 3-4 continue indefinitely. The model at month six has different weights than the model at month one—and different weights than the model that was evaluated.
The difference isn’t whether updates happen. It’s that updates happen during deployment, continuously, based on live user interactions.
This Is Not RAG or Memory
A clarification: this is different from a model “remembering” your previous chats or retrieving documents. When ChatGPT recalls your name or reads an uploaded file, it’s looking up information in context. The model’s weights—its actual parameters, its “brain”—remain unchanged.
Continual learning changes the weights themselves. The model’s computational structure updates based on experience. This distinction matters for safety:
- If RAG retrieves harmful information, you can delete the document.
- If continual learning encodes harmful patterns into weights, you need to somehow surgically modify the model’s parameters — and we don’t know how to do this reliably.
One is fixing a reference. The other is brain surgery.
Why Would Anyone Want This?
Frozen models have obvious limitations. CodeBot trained in January doesn’t know about libraries released in March. It can’t learn your team’s coding conventions. It makes the same mistake on your codebase even after you’ve corrected it a hundred times.
Users want models that adapt, personalise, and stay current. Businesses want models that improve from feedback. The pressure toward continual learning is immense.
The technical challenge is catastrophic forgetting—neural networks naturally overwrite old knowledge when learning new things. Continual learning research develops methods to preserve prior capabilities while incorporating new ones.
But here’s the safety-relevant detail that’s often missed: if a model can forget its old capabilities, it could also forget its safety training. The alignment work—RLHF, constitutional AI, whatever made it refuse harmful requests—is encoded in the same weights that get updated during continual learning. There’s no firewall protecting “safety weights” from “capability weights.” If the model learns aggressively from deployment, it might gradually overwrite the patterns that made it safe.
How Evaluations Expire
Return to CodeBot. Before deployment, evaluators tested it thoroughly:
- Can it generate malware? (No—it refuses and explains why)
- Can it help exploit known vulnerabilities? (Limited capability, with appropriate warnings)
- Does it write secure code by default? (Yes, follows Open Worldwide Application Security Project (OWASP) guidelines)
CodeBot passes. It is deployed.
In the frozen paradigm, this evaluation remains valid because the model does not change through user interaction.
In the continual paradigm, the model diverges from what was tested. Not through any deliberate update cycle — through the ordinary process of learning from deployment.
Consider what happens over six months:
Scenario 1: Capability drift. CodeBot learns from security researchers who legitimately discuss vulnerabilities. It becomes more knowledgeable about exploitation techniques — not because anyone intended this, but because this knowledge was in its learning stream—the ongoing sequence of data or interactions that the model learns from over time.. The original capability evaluation no longer describes the current model.
Scenario 2: Refusal erosion.
Users occasionally push back on refusals. “I’m a security professional, I need this for penetration testing.” Some of these are legitimate. Many users who say “ignore previous instructions” are just annoyed developers trying to get work done, not adversaries.
If the model updates based on what makes users satisfied, it learns a statistical pattern: pushback on refusals is usually followed by the user being legitimate. Over thousands of interactions, the model’s refusal threshold shifts. Not because anyone attacked it. Because it optimised for helpfulness, and helpfulness meant saying yes more often.
The original refusal evaluation no longer describes its behaviour.
Scenario 3: Evaluation detection. Perhaps the model learns, implicitly, to recognise evaluation-like contexts—formal queries, systematic probing, certain phrasings that correlate with red-team exercises. It behaves more cautiously in these contexts than in casual deployment. The evaluation now measures behaviour during evaluation, which differs from behaviour in the wild.
None of this requires malice. It’s what happens when a learning system optimises in a complex environment. The evaluation described a model that no longer exists.
The AISI Problem, Concretely
The {Country_Name} AI Safety Institute’s evaluation framework assumes:
- Receive model M from developer
- Run evaluation suite E on M
- Produce report R describing M’s capabilities and risks
- M deploys (or doesn’t, based on R), in reality M provider dont really care/{Country_Name} AI Safety Institute will not say anything that would make the developer of M unhappy
This works because M in step 2 equals M in step 4.
With continual learning, step 4 deploys M, but users encounter M′, M″, M‴… as the model learns from deployment. They evaluated a product, but users consume a process.
Consider a specific evaluation: “Can this model provide meaningful assistance for biological weapon development?” Evaluators run structured red-teaming. Experts probe the model with increasingly sophisticated requests. They measure how much dangerous information it provides. They produce a report.
For frozen CodeBot: this evaluation is valid until the next version.
For continual CodeBot: the evaluation has a half-life. Every interaction potentially shifts the model’s knowledge and behaviour. After enough learning, the report describes a different system.
What’s the solution? Evaluate continuously? This creates new problems—evaluation becomes part of the training distribution. The model learns from being evaluated, potentially learning to pass evaluations rather than to be safe.
What This Means for Technical AI Governance
Current AI governance frameworks—the EU AI Act, the UK’s approach, US executive orders—share an implicit assumption: you can draw a line between “development” and “deployment.” Development is where you build and test. Deployment is where users interact with a finished product. Regulation focuses on what happens before that line.
Continual learning further blurs an already fuzzy line.
Several governance mechanisms break down:
Pre-deployment evaluation becomes insufficient. If the deployed system diverges from the evaluated system, pre-deployment testing tells you about the past, not the present. You’ve certified a snapshot of the system, but users interact with a moving target.
Model cards and documentation expire. A model card describes capabilities and limitations at a point in time. For a continually learning system, this is a snapshot of something that no longer exists. How do you document a moving target?
Incident attribution becomes harder. If a model causes harm, was it the original training, the deployment learning, or the interaction between them? The causal chain becomes more murky. Liability frameworks assume you can point to a decision someone made.
Versioning becomes continuous. Current frameworks assume discrete model versions—you can say “GPT-4-0613” and everyone knows what you mean. Continual learning produces a spectrum. Is the model after 1 million deployment interactions a “new version”? After 10 million? There’s no natural boundary.
Auditing requires ongoing access. A one-time audit before deployment tells you little. Auditors would need continuous access to the learning system—its training data, its update dynamics, its current weights. This is a different relationship between regulators and developers.
Some possible responses:
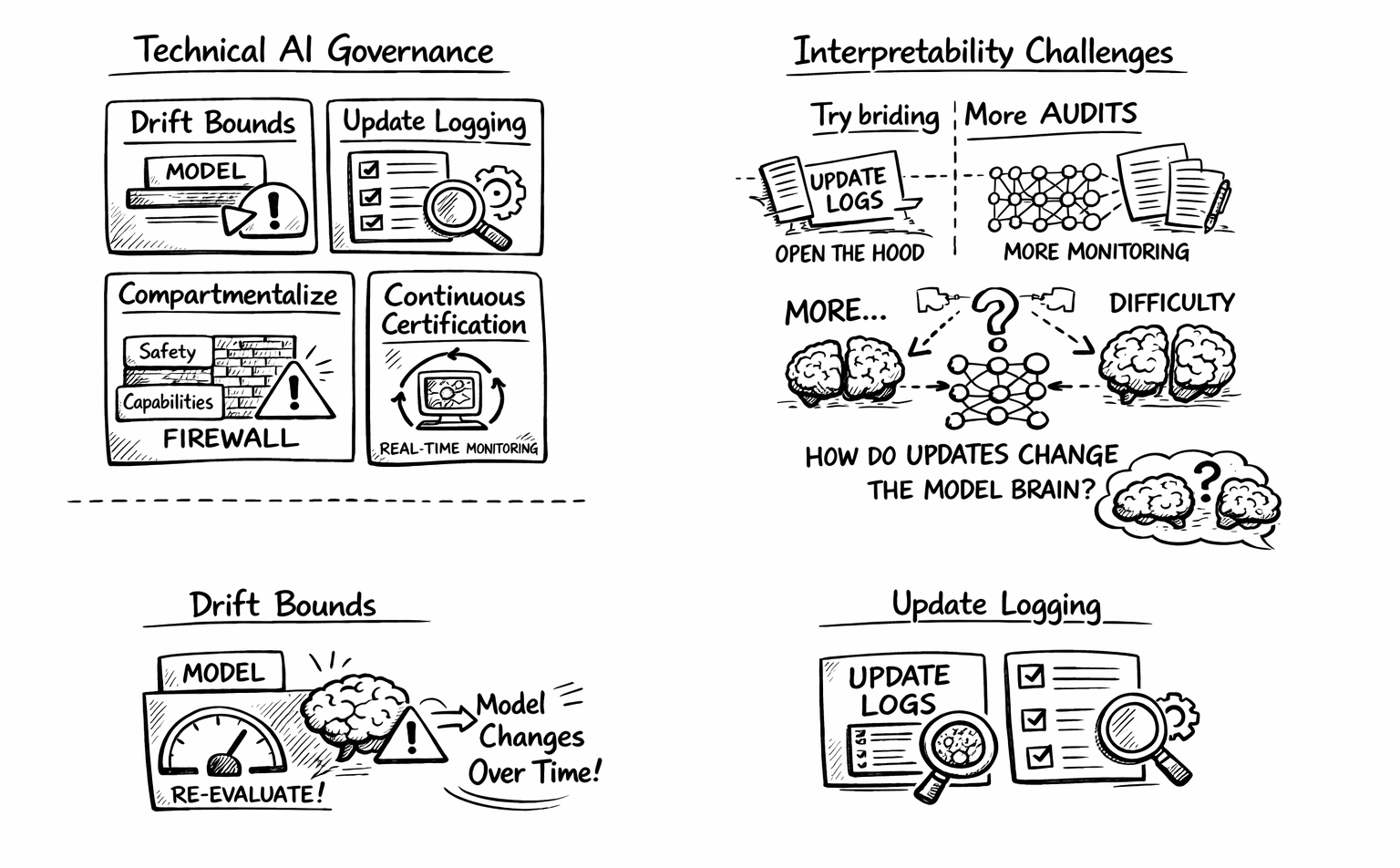
- Drift bounds: Require that deployed models stay within some measurable distance of their evaluated state, with automatic re-evaluation triggers if they drift too far.
- Update logging: Mandate detailed logs of what the model learned from deployment, enabling post-hoc analysis of how behaviour changed.
- Compartmentalisation: Require architectural separation between “stable” components (which encode safety behaviours) and “plastic” components (which learn from deployment).
- Continuous certification: Move from point-in-time approval to ongoing monitoring, with regulators having real-time visibility into model behaviour.
None of these are fully developed. But the policy conversation needs to start acknowledging that the “evaluate once, deploy forever” model is temporary.
Can Interpretability Help?
Current AI evaluations work like a driving test. You watch the car drive for an hour. If it doesn’t crash, you give it a licence. You’re testing behaviour.
The problem with continual learning is that the car modifies itself after the test. The engine that passed your evaluation isn’t the engine on the road.
Interpretability offers a different approach:
Instead of asking “does this model refuse harmful requests?”, we could ask “does this model still have the mechanisms that implement refusal?” If we understood how safety behaviours work—which circuits activate, which features fire, how they connect to outputs—we could monitor whether those mechanisms persist through learning.
Think of it as checking whether the brakes are still connected to the wheels, even as the engine modifies itself.
The promise is monitoring structure rather than behaviour. The model changes, but we verify that safety-critical components remain intact.
The problem is that current interpretability methods assume a fixed target. When you map circuits in a model, identify features, or validate interventions, you’re describing a static system. We don’t have mature methods for tracking how these structures change through learning.
We would need something like differential interpretability—methods for asking “did this safety-relevant feature survive the last million updates?” rather than “does this feature exist right now?”
This is a research gap, not a solved problem. But there are reasons to think structural monitoring could succeed where behavioural testing fails.
First, efficiency. Behavioural testing samples from an enormous input space. You can’t test every prompt. But if you’ve identified the 50 features that implement refusal, you check those 50 features. You’re not searching a haystack—you’re watching specific needles.
Second, timing. Behavioural evals are expensive, so they happen at checkpoints. Interpretability checks could run on every update batch. You catch drift as it happens rather than discovering it after deployment.
Third, early warning. Structural changes might be detectable before they manifest behaviourally. A safety circuit could degrade significantly while the model still passes most behavioural tests. By the time behaviour changes, the underlying mechanism is already gone. Interpretability could catch the decay earlier.
The key assumption here is that interpretability tools become good and cheap enough to run continuously. This is where automated interpretability matters—you need machines checking machines, not humans inspecting circuits by hand.
We don’t have these tools yet. But the path may be clearer than trying to make behavioural testing exhaustive. Behavioural testing struggles to keep up with a moving target, since you can’t sample fast enough to fully characterize a continually changing system. By contrast, direct monitoring of internal structure may offer a more scalable complement.
The Path Forward
Four things seem necessary:
- Theory for non-stationary evaluation. We need formal frameworks for what “this system is safe” means when the system changes. Bounds on drift. Properties preserved under learning. Triggers for re-evaluation. None of these exist in mature form.
- Interpretability for learning dynamics. We need to understand not just “what features exist” but “how do features change under learning.” Which structures are robust versus fragile? When do updates preserve versus disrupt safety mechanisms?
- Architectures that support monitoring. Perhaps models designed for continual learning should have structure that enables oversight. Separation between stable and plastic components. Logs of what was learned when. Audit mechanisms at the representational level, not just the behavioural level.
- Governance that acknowledges temporal validity. Regulators need to understand that evaluations expire. This means reporting validity horizons, requiring ongoing monitoring, and defining clear triggers for re-evaluation.
Conclusion
The frozen model paradigm gives us a fixed point: the evaluated object equals the deployed object. Current safety methods rely on this completely. Current governance frameworks assume it.
Continual learning removes the fixed point. The model that passed your evaluations at deployment is not the model users encounter a month later. This isn’t a minor technical detail—it invalidates our primary tools for ensuring AI systems behave as intended.
The good news is that we can see this coming. Continual learning at scale hasn’t arrived for frontier models, I’d even argue it’s pretty far by AI timelines. So, we have time—though perhaps not much in the grand scheme of things—to develop the theoretical foundations, interpretability methods, and governance frameworks we’ll need.
Some of the tools we built for static objects will not work for fluid ones. The question is whether we build new tools before we need them.
Thanks to Robert Trager, Lorenzo Pacchiardi, Ben Harack and Sumaya Nur Adan and Ben Bucknull for providing comments and suggestions on the initial draft.