
The new scaling paradigm for AI reduces the amount of information a model can learn from per hour of training by a factor of 1,000 to 1,000,000. I explore what this means and its implications for scaling.
The last year has seen a massive shift in how leading AI models are trained. 2018–2023 was the era of pre-training scaling. LLMs were primarily trained by next-token prediction (also known as pre-training). Much of OpenAI’s progress from GPT-1 to GPT-4, came from scaling up the amount of pre-training by a factor of 1,000,000. New capabilities were unlocked not through scientific breakthroughs, but through doing more-or-less the same thing at ever-larger scales. Everyone was talking about the success of scaling, from AI labs to venture capitalists to policy makers.
However, there’s been markedly little progress in scaling up this kind of training since (GPT-4.5 added one more factor of 10, but was then quietly retired). Instead, there has been a shift to taking one of these pre-trained models and further training it with large amounts of Reinforcement Learning (RL). This has produced models like OpenAI’s o1, o3, and GPT-5, with dramatic improvements in reasoning (such as solving hard maths problems) and ability to pursue objectives in an agentic manner (such as performing software-engineering work).
AI labs have trumpeted the new reasoning abilities that RL unlocked, but have downplayed the ending of the remarkable era of pre-training scaling. For example, Dario Amodei of Anthropic said:
Every once in a while, the underlying thing that is being scaled changes a bit, or a new type of scaling is added to the training process. From 2020-2023, the main thing being scaled was pretrained models: models trained on increasing amounts of internet text with a tiny bit of other training on top. In 2024, the idea of using reinforcement learning (RL) to train models to generate chains of thought has become a new focus of scaling.
But there are profound differences between these learning methods which suggest profound changes in how this new era of scaling will play out. I’ve previously written about the importance of the shift to inference-scaling, where the cost-per-use of the models now has to balloon exponentially in order to keep on trend. But here I want to focus on the shift in the method of training.
⁂
A key difference between pre-training and RL is their information efficiency. Pre-training via next-token-prediction provides the model with a token worth of information to learn from for every token the model produces during training. In contrast, training models using RL on machine-checkable tasks requires a long chain of thousands or even millions of tokens before revealing to the model a single bit of information. This means that RL is providing the model much less information to learn from per GPU-hour, and could have serious implications for how much this new RL paradigm can achieve.
Let’s take a look at the actual numbers behind this.
LLMs represent text as streams of tokens, but the precise form of tokenising varies between models and companies. For example, GPT-3 uses about 50,000 distinct tokens, while GPT-4 uses about 100,000. Absent information about how common different tokens are, specifying a particular token out of all these options requires about 16 bits of information. This acts as an upper bound on the amount of information revealed to the model per step of pre-training. One could construct tighter upper bounds by taking into account how much the model already knows about the next token. For example, once it knows the relative frequencies of tokens in text, you could replace 16 bits with the unconditional entropy of a token (~11 bits). You could then use measures like the current log-loss of the model to represent how much information there is left to gain. Given everything a model has learnt from the trillions of tokens it has already seen and everything it can glean from the context of the text preceding this token, the next token becomes quite predictable and so only offers a few bits of new information once pre-training is well underway.
Thus, for the computation needed to generate and learn from an output token (a single forward pass and backwards pass), a model can gain a maximum of 16 bits of information early in pre-training, though we can probably say it is about 3 bits by the end of training (and for most of the training period).
We can sanity check this by looking at the size of GPT-4 and its training data. GPT-4 is about 1012 parameters (so about 3×1013 bits) trained on about 1013 tokens of training data, which comes to about 3 bits of model capacity per token of training data. I’m actually a bit surprised by how close this is, as 3 bits of weights per token is the capacity that would be necessary if it was optimally learning all bits of information in the training signal. My guess is that the inefficiencies in learning from the training signal are being roughly matched by inefficiencies in storing that information as neural net weights. That said, this definitely passes the sanity check.
What about for RL? I don’t know the number of tokens needed for each episode of reasoning in state-of-the-art RL training at major labs, as they don’t usually publish this information. But we do know that DeepSeek-R1 reasoning chains were up to 32,000 tokens long and that their first version used about 12,000 tokens solving AIME tasks while their May 2025 release used about 23,000 tokens per task. So an episode length of >10,000 tokens seems a reasonable ballpark for o1-era training on long reasoning chains. If so, then they were gaining less than 1 bit of information per 10,000 tokens, or 0.0001 bits per token generated. This would have been preceded by RL training at shorter lengths, with higher information-efficiency. But for learning about the longest reasoning chains (which are required for the strongest capabilities) the marginal information gain would be less than 1 bit per 10,000 tokens.
The cutting edge of RL in reasoning is training for longer and longer tasks, as evidenced by METR’s research showing that (for a certain type of research engineering work) the task length that models can succeed on (measured in hours it would have taken a human) has been doubling every 7 months.
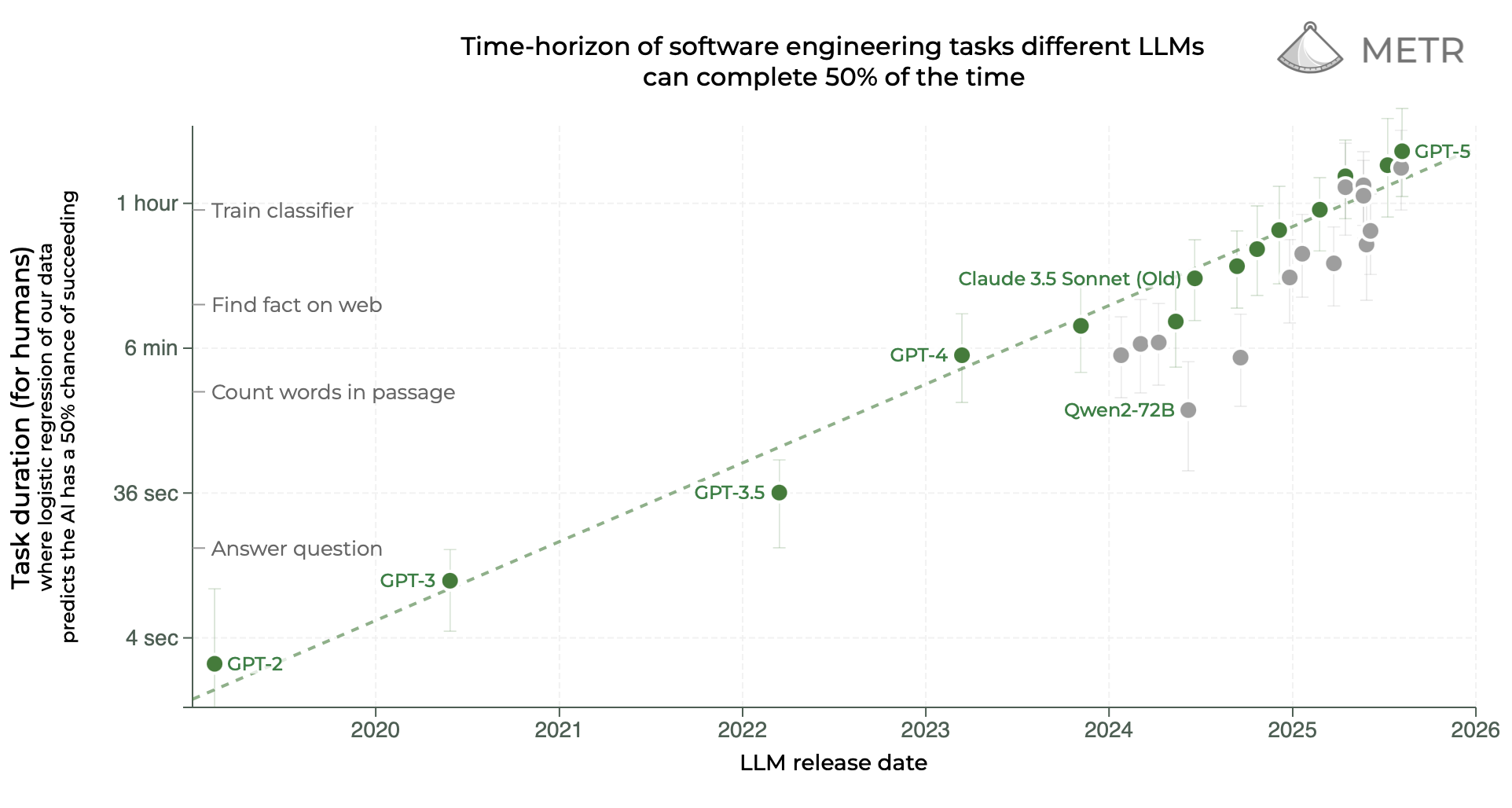
These long horizon tasks require very long reasoning chains, using a lot of tokens. For example, for each task in METR’s HCAST suite, they let o3 use about 16 million tokens (input + output, including reasoning tokens). With this level of token use, o3 was able to reach a 50% success rate on tasks that take humans about 1.5 hours to achieve. It isn’t clear exactly how many output tokens were typically used, or at what level performance plateaued, but 1 million output tokens would be a reasonable guess. Thus if AI labs want to train on tasks like these at the frontier of their systems’ capabilities and the learning sweet-spot of 50% task success rate, they would be looking at an episode length of more than 1 million output tokens. And if such tasks are binary succeed/fail tasks, this would be giving the model less than 1 bit of information per million generated tokens.1
So it looks like on the current margins, there is something on the order of a millionth as much information to be gained per FLOP in RL training compared with pre-training. And this effect will only get stronger as we scale towards more independence and agency in AI systems. As Steve Newman put it:
What happens when we’re trying to train models to independently manage month-long projects? One bit of learning per month is a slow way to make progress.
⁂
We need to be careful when drawing conclusions from these information-theoretic arguments. They show the maximum amount of information that could be learned by the model per forward pass. This ceiling in information being delivered to the model may not be reached, and the model may not optimally learn from the information it receives. The upper-bound for learned information being higher on one training setup doesn’t guarantee that the actual learned information will be higher.
There may also be productive ways of giving the model more than 1 bit of information per episode in RL tasks. An obvious approach, where applicable, is to score partial success with intermediate reward levels. For example, a switch to a 32 bit floating point reward would give a theoretical ceiling of 32 bits. Though even when there are good ways to score partial success, it isn’t clear that a model could usefully extract more than a few useful bits of information from this. That said, if there are clever approaches to widening the amount of information available per episode, they could make a difference.
Furthermore, the value to a user of the model learning some information may depend intimately on what the information was. For example, while knowing whether you succeed or fail in your task is pretty much always relevant and useful to that task, there is a lot of text on the internet that is of very limited value — such as the exact wording of a hastily written comment on a discussion board.
So there is room for these information-theoretic arguments to carry a lot less weight than they initially suggest.
Still, a ratio on the order of 1,000,000x in terms of maximum learnable information per unit of compute is large and probably does have important practical effects. For instance, the size of frontier models compared to their training data suggests that they are learning a lot of the available information from pre-training. Unless they are learning less than 1 bit per 1,000,000 next-token-prediction tasks (and ending up with less than 1 bit of real information per 100,000 parameters), they would appear to be learning more per forward pass than the ceiling on how much RL reasoners or agents can learn when training on tasks at the current frontier task lengths.
How can we square this with the evident success of RL over the last year?
My best guess is that it comes down to the breadth of what the systems are learning. RL is great for learning a narrow task in great depth and bursting through the human-range of abilities without even a kink in the learning curve. Classic examples are DeepMind’s Atari and Go playing agents, which quickly delivered strongly superhuman performance. But RL is not great at generality — the G in AGI. DeepMind had hoped their Atari system could use what it learned when training on one game to help with others (transfer) but instead found that RL training on one game usually impeded learning another. So instead of training a general agent, their initial era of Atari work produced a general framework for training specialist agents. The same was true for board games. They had an agent that was superhuman at Go, but couldn’t play tic-tac-toe against a child.
LLMs and next-token prediction pre-training were the most amazing boost to generality that the field of AI has ever seen, going a long way towards making AGI seem feasible. This self-supervised learning allowed it to imbibe not just knowledge about a single game, or even all board games, or even all games in general, but every single topic that humans have ever written about — from ancient Greek philosophy to particle physics to every facet of pop culture. While their skills in each domain have real limits, the breadth had never been seen before. However, because they are learning so heavily from human generated data they find it easier to climb towards the human range of abilities than to proceed beyond them. LLMs can surpass humans at certain tasks, but we’d typically expect at least a slow-down in the learning curve as they reach the top of the human-range and can no longer copy our best techniques — like a country shifting from fast catch-up growth to slower frontier growth.
We’ve already seen RL post-training achieve impressive success: reasoning models have succeeded at hard tasks like the International Mathematical Olympiad and agentic systems have performed challenging software-engineering tasks. These are big wins for RL on benchmarks we care about. But they are also the precise topics that labs chose to perform the extra training on. When it came to pre-training, there were thousands of off-topic areas and skills (fashion advice, Ming dynasty politics, Harry Potter fanfic…) that the models were training on for every area that the trainers had in mind. This meant impressive new benchmark performance for a model on one topic or skill would correlate with performance gains in untested areas too.
But my hypothesis is that this will become less true the further we get into the RL scaling era — that the much lower information-efficiency of RL is not affecting the depth of ability and knowledge a model has in areas it is specifically trained on, but will be seen in a lack of breadth and generality across the many areas is hasn’t. With GPT-3, 3.5, and 4, there were a host of new abilities that even the people releasing the model had no idea it had learnt until the public got a chance to try it. I think the decreased information-efficiency of RL means we will see a lot less of that going forward.
Such a decrease in generality would be an important downside of the move from scaling up pre-training to scaling up RL training and inference compute — a downside that is hard to avoid due to the much lower information-efficiency of RL on long tasks. Combined with the much higher costs to deploy a system whose intelligence relies on scaling up inference compute, we may be entering an era where continued progress on targeted benchmarks means less than it once did.
And it is another sign that we’ve passed an important juncture in modern AI. There are such profound differences between the scaling of pre-training and the scaling of RL that we shouldn’t be surprised if many important trends and mental models about AI progress start to break.
1 1 bit per episode is actually the maximum for succeed/fail RL tasks. You reach it when training at a difficulty level where the model is succeeding 50% of the time. If it is succeeding closer to 0% or 100%, the reward given is less of a surprise so conveys less information. This could be an issue if trying to avoid the long-episode inefficiency by training on shorter length tasks that the model is already good at, or if the model requires training on tasks it is already competent at to learn how to boost reliability to the >99% rates required for many practical uses.